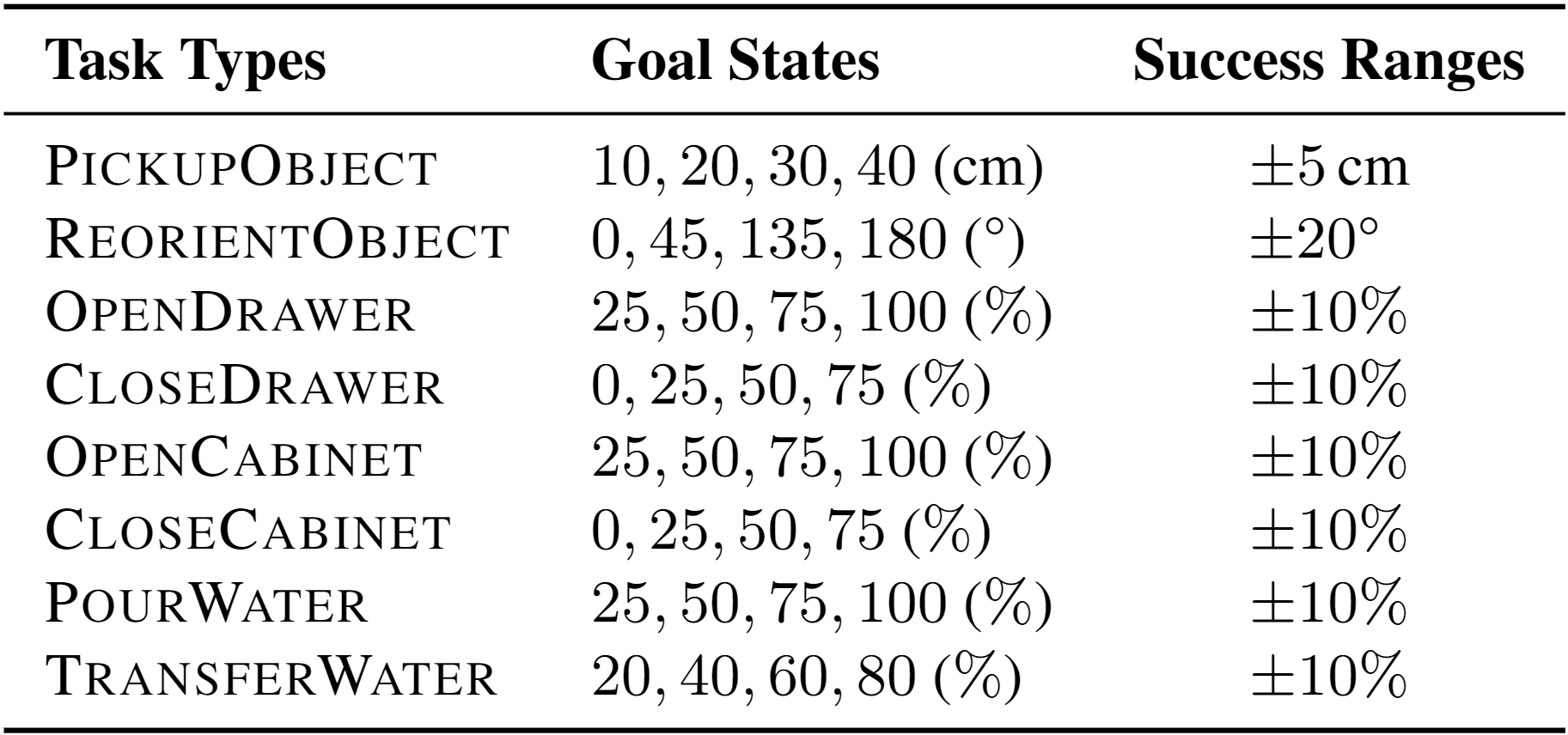
Tasks
The current version of ARNOLD includes eight tasks with various goal state variations. For each task, we define a success range around the goal state wherein the robot should maintain the object state for two seconds to succeed. Performing these tasks requires capabilities in language grounding, friction-based grasping, continuous state understanding, and robot motion planning.
BaseTask
Tasks are defined in tasks/. All the task classes inherit a common class BaseTask, which is defined in tasks/base_task.py. The BaseTask class defines some common methods. For example, calling the render() method will return a multi-view RGB-D observation.
Each specific task class implements several methods based on BaseTask. Each task episode starts with a call of reset(), and proceeds via calling step(). We adopt a two-phase learning setting: the robot learns the end effector pose for grasping the target object in the first phase, and learns the goal pose for task success in the second phase. In other words, to complete each task, the step() method should be called twice, and the task will be a success only if both poses are precisely estimated. The arguments and returns of reset() and step() are as follows:
def reset(self,
robot_parameters: RobotParameters,
scene_parameters: SceneParameters,
object_parameters: List[ObjectParameters],
robot_base: Union[List, Tuple],
gt_actions: Union[List, Tuple],
) -> Dict:
"""
Return a `Dict` (observation)
"""
def step(self,
act_pos: np.ndarray,
act_rot: np.ndarray,
render: bool,
use_gt: bool,
) -> Tuple
"""
Return a `Dict` (observation) and an `int` (success indicator):
"""
Object
In PickupObject and ReorientObject, the robot is instructed to manipulate a bottle to achieve different goals. In PickupObject, the object initially stands on the ground and the goal specifies the desired height above the ground. In ReorientObject, the object initially lies horizontally on the ground (the state value equals 90°) and the goal specifies the angle between the object’s orientation and the upright orientation. These two tasks concern the basic skills of translating/rotating objects and the grounding of distances/angles.


PickupObject. This task consists of three stages: pre-grasping, grasping, and manipulating the object. Pre-grasping requires the robot to move the end effector to a small distance away from the target object. After that, grasping requires the robot to approach the object and close the gripper to get ready for interaction. Finally, the robot needs to manipulate the object to reach the goal state. Such a three-stage setting also applies to other tasks except fluid tasks.ReorientObject. This task class is similar toPickupObject, except they differ in task name and success checker.
Articulation
There are four articulation tasks: OpenDrawer, CloseDrawer, OpenCabinet, and CloseCabinet. The goal value of each task specifies the geometric state of the articulated joint, either in terms of distance (for prismatic joint) or angle (for revolute joint). The initial state can be any value smaller/larger than the goal for opening/closing task. These four tasks further enhance the abilities of manipulation and state grounding in articulated objects.




The articulation tasks adopt the same three-stage setting introduced in PickupObject. Differently, in articulation tasks, the manipulation process in the last stage requires motion interpolation to obtain smooth trajectories for the end effector to follow. Specifically, in Object tasks, the robot can directly plan motion towards the goal pose while holding the object. However, while holding the articulation handle in Articulation tasks, directly following a goal pose that is far away would cause the gripper to depart from the handle due to physics. So, for fine-grained control, motion interpolation is necessary.
OpenDrawer. To manipulate prismatic joint, this task adopts linear interpolation between the handle position and the goal position. The number of interpolation points is proportion to the distance.CloseDrawer. This task class is almost equivalent toOpenDrawer, except for a different task name.OpenCabinet. To manipulate revolute joint, this task adopts spherical linear interpolation (Slerp) between the initial angle and the goal angle. The number of interpolation points is proportion to the angle difference.CloseCabinet. This task class is almost equivalent toOpenCabinet, except for a different task name.
Fluid
In PourWater and TransferWater, the object to manipulate is a cup containing water, and the goal specifies the percentage of water to be poured out or into another cup. The goal values are specified relative to the initial amount of water in the cup. These two tasks go beyond rigid-body objects to challenge the robot’s ability to manipulate containers with fluid, requiring grounding goal state values to fluid volume.


Different from the three-stage setting in the aforementioned tasks, the fluid tasks consist of six stages: (1,2) are the same, i.e., pre-grasping and grasping; (3) lift the cup up; (4) translate horizontally to the position before pouring; (5) pour; (6) rotate the cup back to upright orientation.
PourWater. Similar toCabinettasks, the fluid tasks also adopt spherical linear interpolation (Slerp) for motion interpolation. By controlling a constant angle velocity, the goal pose of the pouring action can represent a corresponding pouring volume, thus relating the learning of target volume to the learning of goal pose. When the cup returns to the upright orientation, the checker determines success by examining the volume of the remaining water.TransferWater. This task class is similar toPourWater. Apart from a different task name, this task has a second cup and an extra success condition that the split water should be less than a certain amount.