Data
As mentioned in Tasks, each task consists of several stages to complete. A corresponding motion planner is pre-defined for each task to complete the stages. The motion planner operates according to stage-wise keypoints, on which the diversity of demonstrations is highly dependent. To address this, we collect about 2k human annotations of task configurations (e.g., object positions). Moreover, we broaden the data variations with additional relative positions and robot shifts. After the data generation process, we run inference with ground-truth keypoints to curate valid demonstrations. Finally, we collect 10k valid demonstrations for ARNOLD benchmark, with each demonstration containing 4–6 keyframes. See data statistics below:
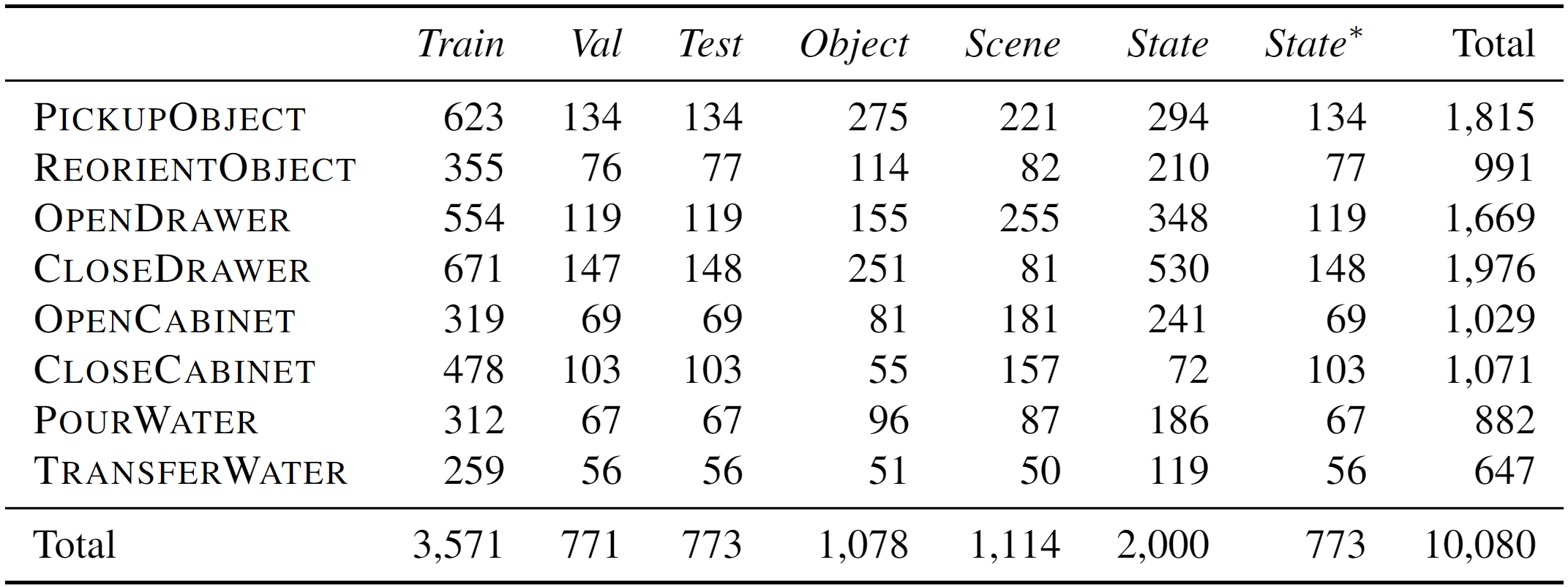
Split
Generalization is a major focus of ARNOLD. We randomly split the objects, scenes, and goal states into seen and unseen subsets, respectively. We create the Normal split by gathering data with seen objects, scenes, and states. This split is further shuffled and divided into Train/Val/Test sets proportioned at 70%/15%/15%. Furthermore, we create the Generalization splits Novel Object/Scene/State by gathering data with exactly one of the three components (i.e., objects, scenes, and goal states) unseen; e.g., the Novel Object split comprises data of unseen objects and seen scenes/states. In addition, we create an extra evaluation split Any State, which incorporates seen objects/scenes and arbitrary goal states within a continuous range, e.g., 0%–100%.
Language
For each demonstration, we sample a template-based language instruction with our language generation engine. We design several instruction templates with blanks for each task, and each template can be lexicalized with various phrase candidates. For example, the template “pull the [position] [object] [percentage] open” may be lexicalized into “pull the top drawer 50% open”. In addition to the representation with explicit numbers, we also prepare a candidate pool of equivalent phrases (e.g., “fifty percent”, “half”, “two quarters”) for random replacement. We present a few examples of instruction templates as follows:

Format
Each demonstration is saved in npz format, which is structured as below (here only present important elements for simplicity):
demonstration:
numpy.lib.npyio.NpzFilegt: numpy.ndarray (list)dict:: recorded information of each keyframeimages -> listdict:: RGB-D observation from each camerargb -> numpy.ndarraydepthLinear -> numpy.ndarraycamera -> dict:: camera parameters...
instruction -> strposition_rotation_world -> tuple:: end effector pose in world framenumpy.ndarray:: position (xyz, y axis upward, in cm)numpy.ndarray:: rotation (quaternion, wxyz)
gripper_open -> boolgripper_joint_positions -> numpy.ndarray:: gripper joint valuesrobot_base -> tuple:: robot base pose in world framenumpy.ndarray:: position (xyz, y axis upward, in cm)numpy.ndarray:: rotation (quaternion, wxyz)
diff -> float:: the difference between current state and goal state...
info: numpy.ndarray (dict):: environment configurations, access thedictviaitem()scene_parameters -> dict:: arguments ofSceneParametersrobot_parameters -> dict:: arguments ofRobotParametersobjects_parameters -> listdict:: arguments ofObjectParameters
config -> dict:: misc configurationsrobot_shift -> list:: robot position shift (xyz, y axis upward, in cm)
Dataloader
We provide a single-task dataset class ArnoldDataset and a multi-task dataset class ArnoldMultiTaskDataset in dataset.py.
ArnoldDataset. For each task, the demonstrations are maintained inepisode_dict, which is adictorganized by categorizing different objects and phases.MetaData: { 'img': img, # [H, W, 6], rgbddd 'obs_dict': obs_dict, # { {camera_name}_{rgb/point_cloud}: [H, W, 3] } 'attention_points': obj_pos, # [3,] 'target_points': target_points, # [6,] 'target_gripper': gripper_open, # binary 'low_dim_state': [gripper_open, left_finger, right_finger, timestep] 'language': language_instructions, # str 'current_state': init_state, # scalar 'goal_state': goal_state, # scalar 'bounds': task_offset, # [3, 2] 'pixel_size': pixel_size, # scalar } ArnoldDataset.episode_dict: { obj_id: { 'act1': List[MetaData], 'act2': List[MetaData], } }
Referring to the structure of
episode_dict, fetching a piece of data requires three values: anobj_id, the phase (act1oract2), and an index in the correspondingList[MetaData]. There are two modes to fetch data from the dataset: index and sample. In both modes, the phase (act1oract2) is sampled according tosample_weightsbecause of the phase imbalance. In index mode, we get the data by calling__getitem__()and passing an index to retrieve data sequentially. The provided index maps to a uniqueMetaData. In sample mode, we get the data by callingsample(), where both theobj_idandMetaDataindex are uniformly sampled.ArnoldMultiTask. This is a wrapper upon the single-task classArnoldDataset. Specifically, it contains adictnamedtask_dict, whose keys are task names and corresponding values areArnoldDataset.
Since the language encoding modules are fixed, we create a class InstructionEmbedding in dataset.py to store the embedding caches. When forwarding, the embedding of language instruction will be computed and added to the cache unless it already exists in the cache.